Improving cache performance
Classifying Cache Misses
Three major categories of cache misses:
Compulsory Misses: cold start misses or first reference misses. The first access to a block is not in the cache, so the block must be loaded in the cache from the MM. These are compulsory misses even in an infinite cache.Capacity Misses: can be reduced by increasing cache size. If the cache cannot contain all the blocks needed during execution of a program, capacity misses will occur due to blocks being replaced and later retrieved.Conflict Misses: can be reduced by increasing cache size and/or associativity. If the block-placement strategy is set associative or direct mapped, conflict misses will occur because a block can be replaced and later retrieved when other blocks map to the same location in the cache.
Improving cache performance
$$\text{AMAT} = \text{Hit Time} + \text{Miss Rate} \times \text{Miss Penalty}$$
In order to improve the AMAT we need to:
- Reduce the miss rate
- Reduce the miss penalty
- Reduce the hit time
The overall goal is to balance fast hits and few misses.
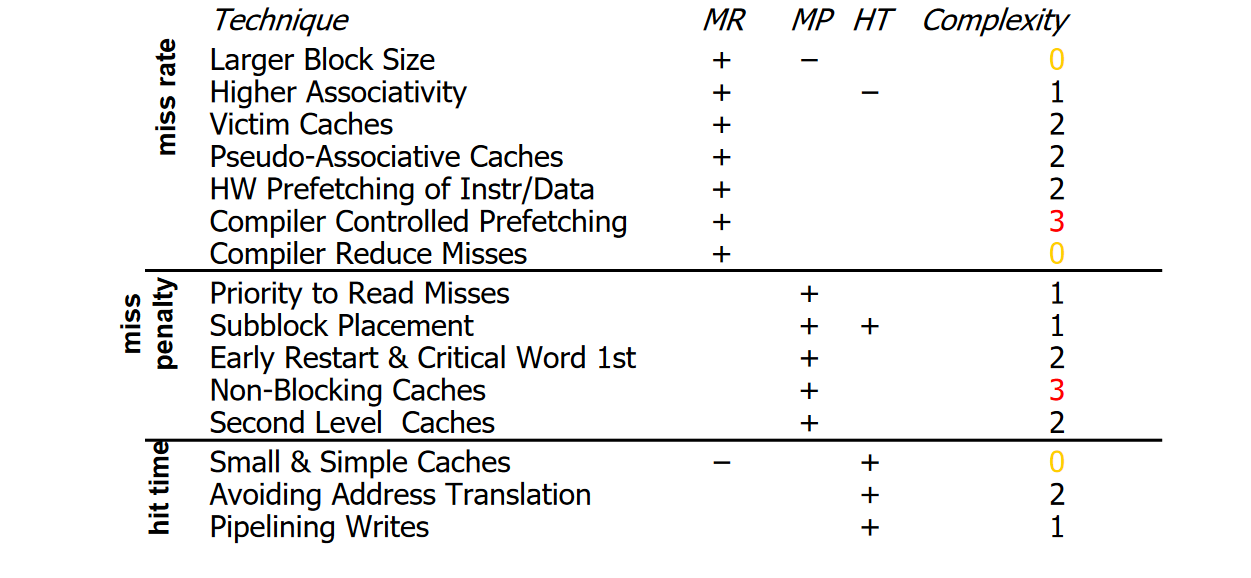
1) Reducting the miss rate
1.1) Reducing Misses via Larger Cache Size
Obvious way to reduce capacity misses: to increase the cache capacity.
Drawbacks: Increases hit time, area, power consumption and cost
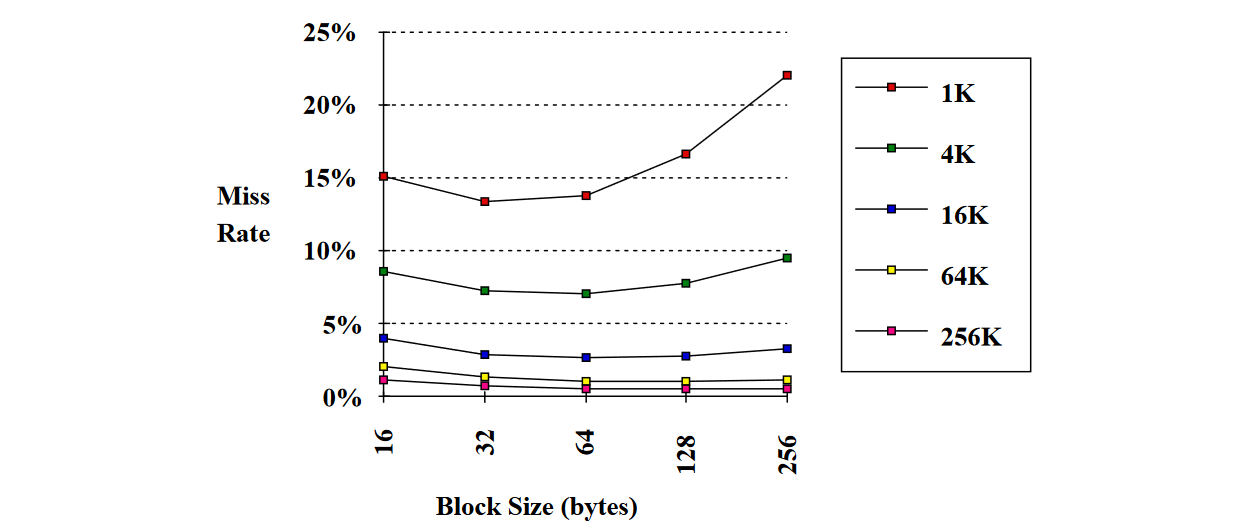
1.2) Reducing Misses via Larger Block Size
Increasing the block size reduces the miss rate up to a point when the block size is too large with respect to the cache size.
Larger block size will reduce compulsory misses taking advantage of spatial locality.
Drawbacks:
- Larger blocks increase miss penalty
- Larger blocks reduce the number of blocks so increase conflict misses (and even capacity misses) if the cache is small.
1.3) Reducing Misses via Higher Associativity
Higher associativity decreases the conflict misses.
Drawbacks: The complexity increases hit time, area, power consumption and cost.
A rule of thumb called "2:1 cache rule": Miss Rate Cache Size N = Miss Rate 2-way Cache Size N/2
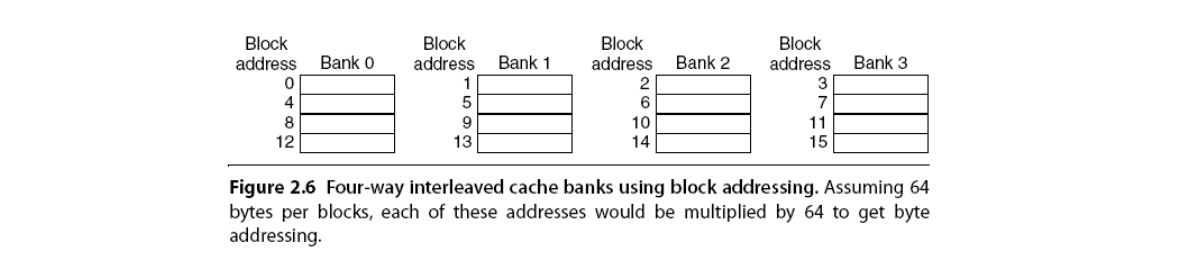
Multibanked Caches
Multibanked caches introduce a sort of associativity. Organize cache as independent banks to support simultaneous access to increase the cache bandwidth.
Interleave banks according to block address to access each bank in turn (sequential interleaving):
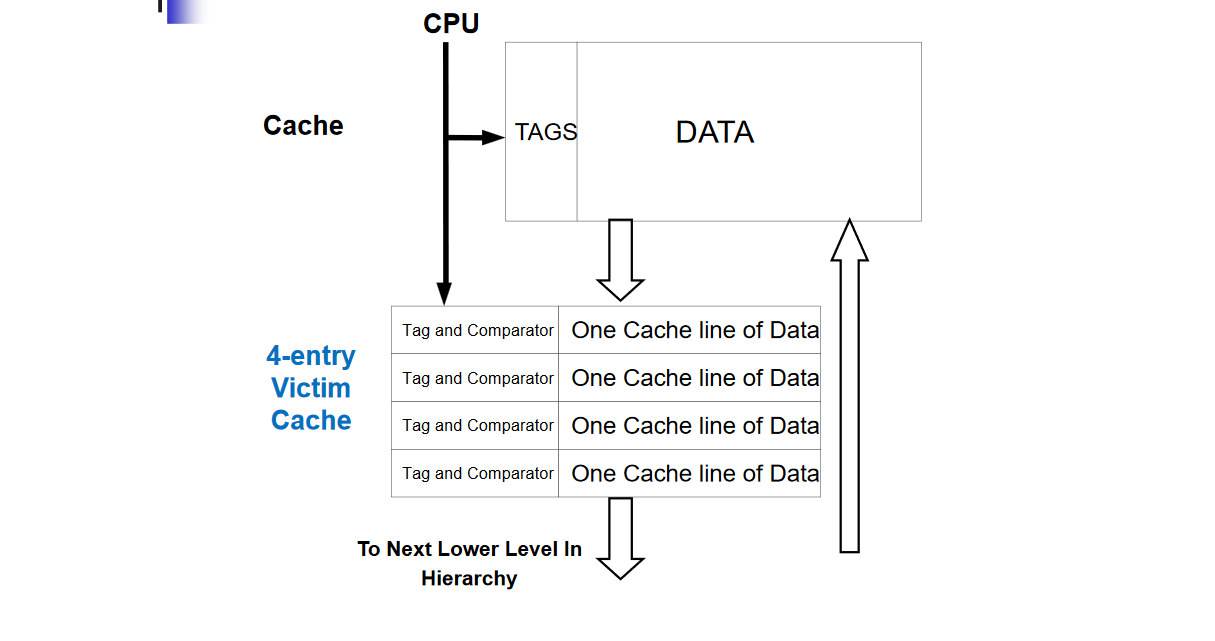
1.4) Reduce Misses (and Miss Penalty) via a “Victim Cache”
Victim cache is a small fully associative cache used as a buffer to place data discarded from cache to better exploit temporal locality. It is placed between cache and its refilling path towards the next lower-level in the hierarchy and it is checked on a miss to see if it has the required data before going to lower-level memory.
If the block is found in Victim cache the victim block and the cache block are swapped.
1.5) Reducing Misses via Pseudo-Associativity and Way Prediction
In 2-way set associative caches (way prediction) use extra bits to predict for each set which of the two ways to try on the next cache access (predict the way to pre-set the mux):
- If the way prediction is correct Hit time
- If way misprediction Pseudo hit time in the other way and change the way predictor
- Otherwise go to the lower level of hierarchy (Miss penalty)
In direct mapped caches (Pseudo-Associativity) divide the cache in two banks in a sort of associativity.
- If the bank prediction is correct Hit time
- If misprediction on the first bank, check the other bank to see if there, if so have a pseudo hit (slow hit) and change the bank predictor
- Otherwise go to the lower level of hierarchy (Miss penalty)

1.6) Reducing Misses by Hardware Pre-fetching of Instructions and Data
To exploit locality, pre-fetch next instructions (or data) before they are requested by the processor. Pre-fetching can be done in cache or in an external stream buffer.
Drawback: If pre-fetching interferes with demand misses, it can lower performance
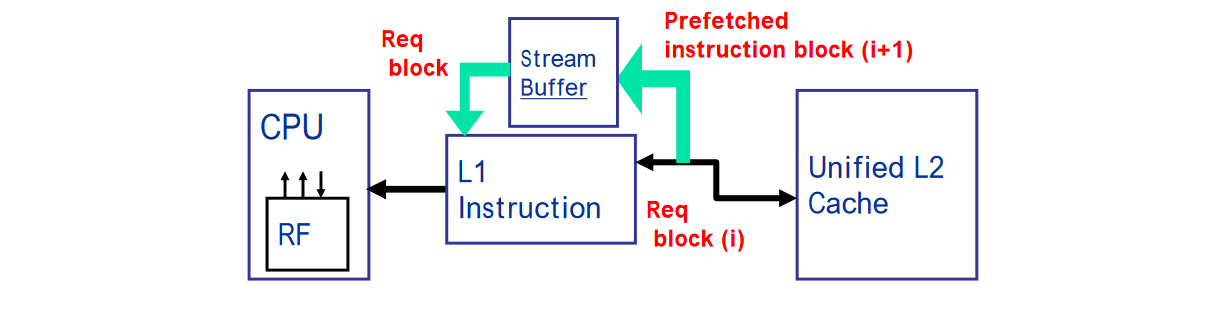
Instruction pre-fetch in Alpha AXP 21064
Fetch two blocks on a miss; the requested block (i) and the next consecutive block (i+1). Requested block placed in cache, while next block in instruction stream buffer.
If miss in cache, but hit in stream buffer, move stream buffer block into cache and pre-fetch next block (i+2).
1.7) Reducing Misses by Software Pre-fetching Data
Compiler-controlled pre-fetching (the compiler can help in reducing useless pre-fetching): Compiler inserts pre- fetch LOAD instructions to load data in registers/cache before they are needed.
- Register Pre-fetch: Load data into register
- Cache Pre-fetch: Load data into cache
Note: Issuing pre-fetch instructions takes time (instr. overhead).
1.8) Reducing Misses by Compiler Optimizations
Apply profiling on SW applications, then use profiling info to apply code transformations.
Managing instructions
Reorder instructions in memory so as to reduce conflict misses and use profiling to look at instruction conflicts
Managing Data
-
Merging Arrays: improve spatial locality by single array of compound elements vs. 2 arrays (to operate on data in the same cache block)

-
Loop Interchange: improve spatial locality by changing loops nesting to access data in the order stored in memory (re-ordering maximizes re-use of data in a cache block)

-
Loop Fusion: improve spatial locality by combining 2 independent loops that have same looping and some variables overlap

- Loop Blocking: Improve temporal locality by accessing “sub-blocks” of data repeatedly vs. accessing by entire columns or rows. Subdivide the matrix into BxB blocks that fit the cache size to maximize accesses to data loaded in the cache before they are replaced



2) Reducing miss penalty
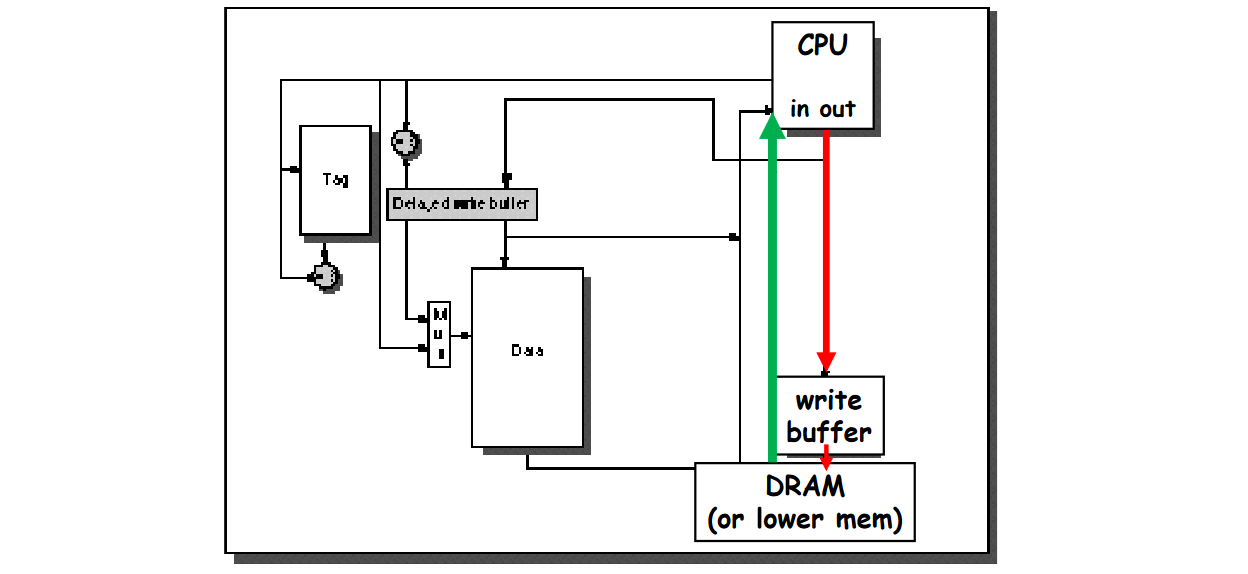
2.1) Read Priority over Write on Miss
Giving higher priority to read misses over writes to reduce the miss penalty. The write buffer must be properly sized: Larger than usual to keep more writes in hold.
Drawback: This approach can complicate the memory access because the write buffer might hold the updated value of a memory location needed on a read miss => RAW hazard through memory.
2.2)
3) Reducing hit time
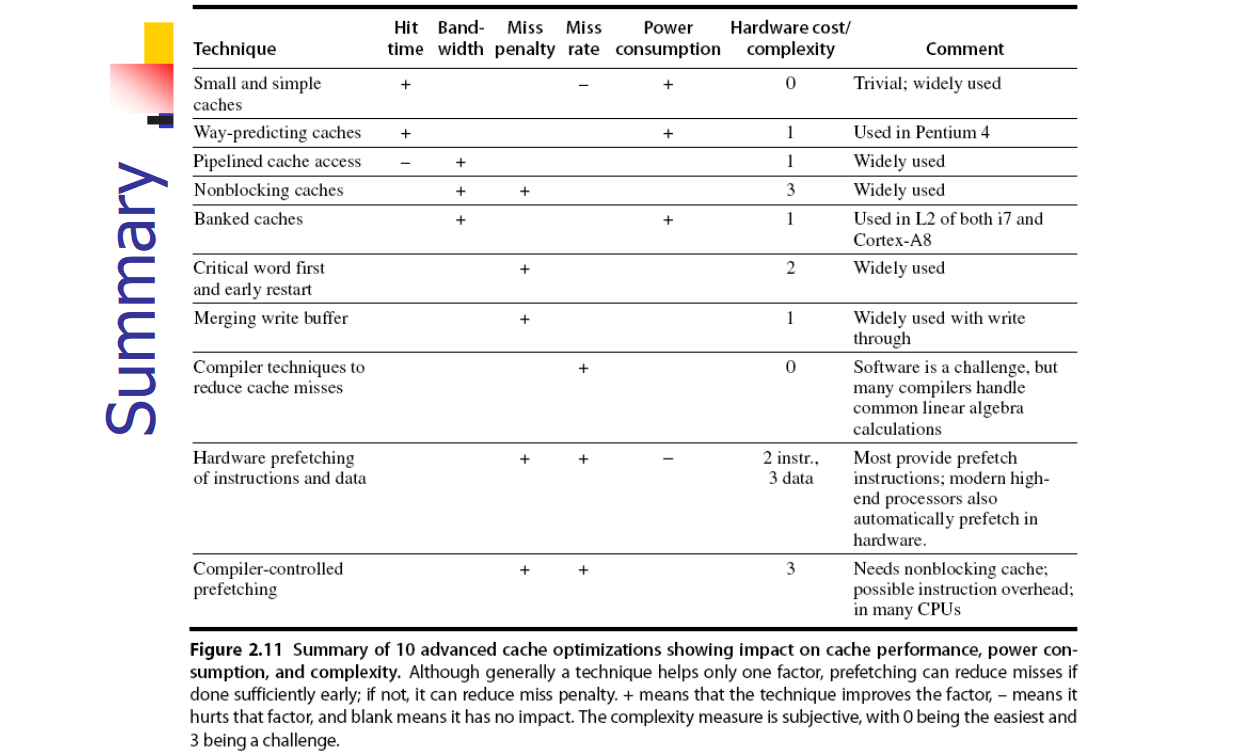
Cache Optimization Summary